Noob_The_ Jacky
Member
- Joined
- Dec 21, 2020
- Messages
- 14
- Programming Experience
- Beginner
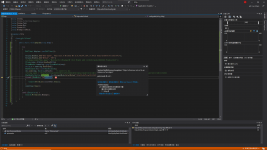
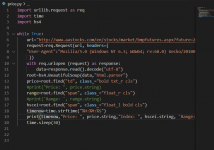
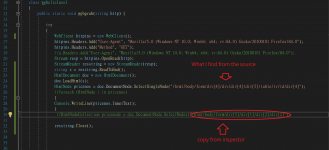
method for crawler:
public static void webgrab(string http) {
WebClient httpins = new WebClient();
httpins.Headers.Add("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:84.0) Gecko/20100101 Firefox/84.0");
httpins.Headers.Add("Method", "GET");
Stream resp = httpins.OpenRead(http);
StreamReader resstring = new StreamReader(resp);
string s = resstring.ReadToEnd();
HtmlDocument doc = new HtmlDocument();
doc.Load(resp, Encoding.Default);
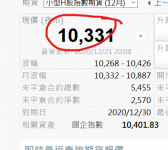
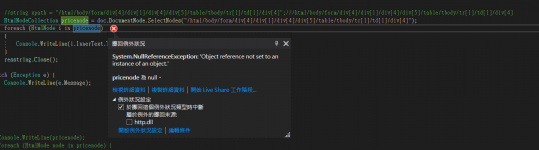
HtmlNodeCollection pricenode = doc.DocumentNode.SelectNodes("/html/body/form/div[4]/div[1]/div[4]/div[5]/table/tbody/tr[1]/td[1]/div[4]");
foreach (HtmlNode i in pricenode)
{
Console.WriteLine(i.InnerText.Trim());
}
resstring.Close();
}I think it didn't work because I fail the convert the stream to htmldocument , or maybe the xpath can't find the right way in the htmlnode. But I really check so many times, it just the same as what I find and also what really working, except the link and the specific info..
What could go wrong?
Main:
static void Main(string[] args)
{
webcliclassl.webgrab("http://www.aastocks.com/tc/stocks/market/bmpfutures.aspx?future=200300");
}Attachment shows that little things i want!
Tell me what's go wrong. Please!