CrashedCrash
New member
- Joined
- Aug 24, 2020
- Messages
- 1
- Programming Experience
- 1-3
Dear Community I need ur help,
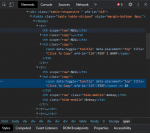
im strugglin right now with it to find an element in html source over the wfd-id to copy the blank text from there.
in the attachment u find the html code. Maybe one of u have an solution :'(
would IE11 load the wfd-id`s I can grap it easy but it dont do.
im strugglin right now with it to find an element in html source over the wfd-id to copy the blank text from there.
in the attachment u find the html code. Maybe one of u have an solution :'(
would IE11 load the wfd-id`s I can grap it easy but it dont do.
Example:
if (WebBrowser.ReadyState == WebBrowserReadyState.Complete)
{
foreach (HtmlElement Element in WebBrowser.Document.GetElementsByTagName("span"))
{
if (Element.GetAttribute("wfd-id") == "136")
{
WebBrowser.Document.ExecCommand("Copy", false, null);
label1.Text = Clipboard.GetText();
}
}
}Attachments
Last edited: